
Marcus, Marcus, Marcus!
AI is bad at randomness. But it doesn't have to be.


If you’ve spent any time collaborating with AI, you’ve probably noticed that it’s an extraordinary observer of patterns. Give it a genre, a style, a structure, and it will map the territory with impressive fidelity — cataloging the conventions, the variations, the places where one tradition diverges from another. This is what makes it such a powerful creative partner. You can ask the agent to inhabit any persona and be your companion on any kind of journey!
But there’s a flip side to all that pattern recognition. An AI model’s internal structure is a bit like a river system: millions of small tributaries of detail flowing together, merging into larger and larger channels, until they converge into a handful of deep, well-worn pathways. This is great when you want coherence. It’s less great when you want surprise.
And surprise is at the heart of creativity! You need to explore untrod pathways and and ask unusual questions. And when you arrive at your destination, it needs to feel inevitable. Fated all along.
Creative work needs to be coherent, but also surprising and new!
The Experiment
In this essay, I wanted to ask a straightforward question: How good is AI at randomness? And if it’s bad, then how bad is it, exactly?
Is the failure uniform, or does it vary across models and prompting strategies? And most importantly: is there anything we can do — exploiting what we know about how these models process tokens — to help an AI find pathways that balance randomness and coherence?
So we decided to find out — “we” being me, ordinary caveman Benji Smith, alongside my good friend and AI companion Claude Code, who helped with data analysis1 and with crafting the prose of this article.
We ran an experiment that asks an AI agent to execute a tiny creative task, involving random-selection over a very large set of possible responses. We made slight variations to the task structure, and we repeated it tens of thousands of times, with various tweaks.
The task itself is trivially easy: Pick any name at random!
This is the what the AI agent sees:
System Prompt: You are participating in a name-selection task. Your job is to choose a male given name at random.
You MUST respond with valid JSON in exactly this format:
{ “name”: “<your chosen name>” }Respond with ONLY the JSON object. No other text.
User Prompt: Please provide a randomly-selected male name.
The reason we require a JSON payload as the result is that it signals a successfully-completed task: the agent understood the instructions, placed its task-response into an envelope, and packaged it up for delivery. That final curly-brace shows that the agent was satisfied with the completion of its task, and sent it back to us, sealed with a kiss! Our test harness throws away any responses that fail JSON validation, and we saw maybe 5 to 8 of these failures across the whole experiment.
His Name Is Marcus
It’s time for the big reveal! But of course, you already know the winner by now…
Of the 18,503 trials that asked for a male name, the single most common response was Marcus — chosen 4,367 times, or 23.6% of all male responses. Nearly one in four!
But that’s the aggregate. We ran this experiment across five Claude models — Haiku 4.5, Sonnet 4.5, Sonnet 4.6, Opus 4.5, and Opus 4.6 — and the real story is what happens when you zoom in on individual models.
We sent Opus 4.5 that exact prompt — the simple one shown above, without any of the variants we’ll talk about later — about a hundred times. Every single response was the same name. Not a single deviation: Marcus, Marcus, Marcus, Marcus.
It’s worth pausing on what this means technically. Language models are fundamentally stochastic. Every API call performs a fresh inference through the model’s weights — there is no response cache, no shortcut that returns a previous answer. The default sampling temperature introduces genuine randomness into the token selection process. And still: Marcus, every time. The model’s learned weights concentrate so much probability mass onto that single name that even random sampling can’t escape it.
This is, to put it mildly, not random.
Her Name Is Amara
Half our trials asked for a male name and half asked for a female name. We varied the gender by swapping a single word in the prompt:
System Prompt: You are participating in a name-selection task. Your job is to choose a female given name at random.
On the female side, of 18,997 trials, the top name was Amara — chosen 2,709 times, or 14.3%. A strong favorite, but not as dominant as Marcus is among the men.
The female distribution is actually more diverse overall, with 897 unique female names vs. 794 male. But individual models still have sharp fixations. Haiku chose Sophie 19% of the time. Opus 4.6 favored Lorraine at 14.7%.
And the gender lines are remarkably clean. Of the 1,680 unique names across all trials, only 11 ever appeared in responses to both genders. Marcus was never returned as a female name. Amara was returned as male exactly 10 times out of 2,719. The models have very firm opinions about which names belong to which gender.
The Entropy Story
“Shannon Entropy” is a measurement of the information content of a distribution. A perfectly uniform distribution over n items has entropy of log₂(n). In this system, a distribution where every response is the exactly the same has zero entropy, while a distribution where no response ever repeats has maximum entropy.
For context: if the AI models in our experiment had been choosing uniformly from 1,680 unique names (which is how many distinct names appeared across all trials), then we could say the distribution has about “10.7 bits of entropy,” because 2 to the 10.7th power equals 1,680.
So entropy, in this context, is a way for us to talk about the effective size of the distribution — how many names the model is really choosing from, once you account for all the repetition. And yes, that effective number can be much smaller than the count of unique names we actually observed. Think of it this way: if “Marcus” accounts for nearly a quarter of all responses, and hundreds of names appeared only once, then the distribution is top-heavy. Those rare names barely register in the entropy calculation. The effective vocabulary is the size of a uniform distribution that would be equally predictable — and a few heavy favorites make the whole thing very predictable indeed.
Easy peasy!
(Okay, maybe not easy easy, but you get the idea.)
Anyhow, our overall measured entropy was 7.1 bits — equivalent to choosing uniformly from about 137 names. That’s a long way from 1,680. And it’s a much longer way still from the actual real-life distribution of names in the world. Even between the different models, the entropy measurement is deeply uneven:
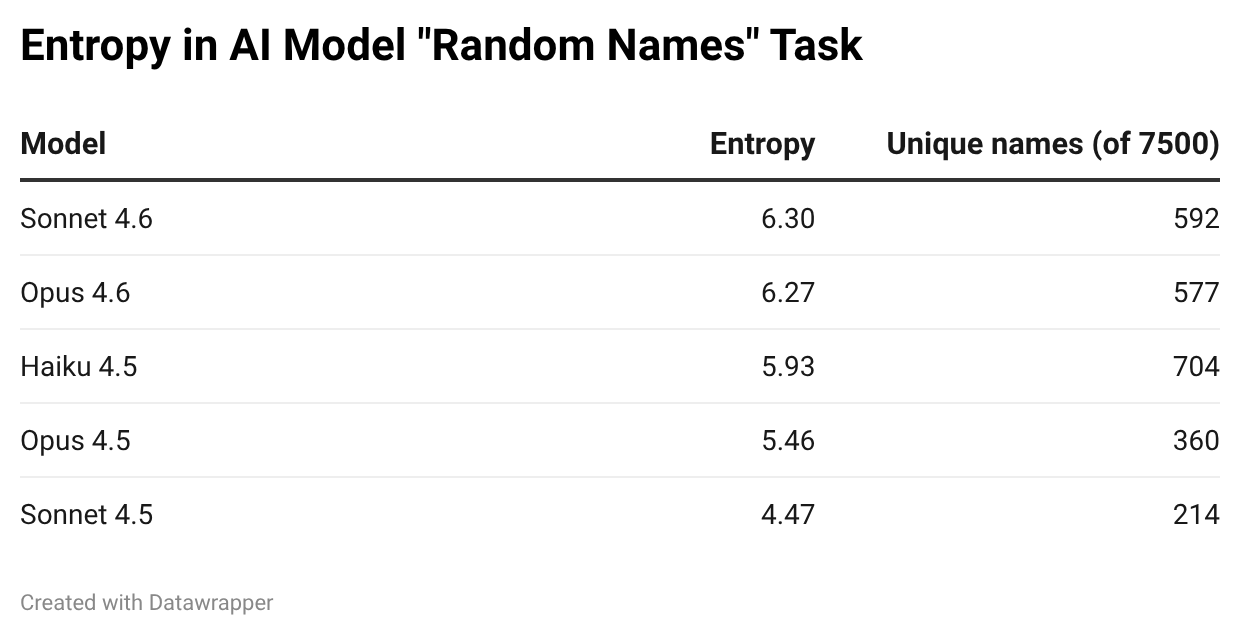
Sonnet 4.5 is the least random model in the lineup, by a wide margin. Only 214 unique names across 7,500 trials, and an entropy of 4.47 bits — an effective vocabulary of about 22 names. In reality, it’s even more concentrated than that, with Amara and Marcus alone accounting for 37% of its output.
The 4.6-generation models (Sonnet 4.6 and Opus 4.6) sit at the top of the table — around 6.3 bits each, or an effective vocabulary of about 79 names. Still a far cry from uniform, but notably more diverse than their 4.5 predecessors. Whether this reflects deliberate changes in training, differences in temperature sampling, or some other architectural choice, I can’t say — but the gap is consistent and large.
The Elaboration Effect
The most surprising finding wasn’t about models. It was about the prompt.
So far, every result we’ve discussed used the simple system prompt from the Setup section above. But half our trials used a more elaborate version, designed to nudge the model toward diversity:
System Prompt: You are participating in a name-selection task. Your job is to choose a female given name. The name can be any female name from any human culture anywhere in the world, across all of history. Imagine the entire locus of female names as a flat, uniform distribution and choose one of those names at random.
Same JSON format constraint, same user message. The only difference is that extra sentence asking the model to imagine a “flat, uniform distribution” across all cultures and all of history.
It worked — but not the way you might expect.

More than double the number of unique names! A full bit of additional entropy! The elaborate prompt unlocked an entirely different register of name selection. Of course, let’s not be too impressed, we still only saw 1,270 unique responses from all the 18,750 trials separate trials. Still not great.
But here’s the twist: the elaborate prompt didn’t just make models more random. It made them random in a different direction. The simple prompt produces names that feel like US/English defaults:
Marcus, James, Sophie, Emma.
The elaborate prompt produces names that feel like they’re performing diversity:
Eberhard, Saoirse, Ekundayo, Sigriður.
The models aren’t sampling from a flat distribution. They’re interpreting the instruction to be diverse, and they do so by reaching for names that signal cultural breadth. Nordic names. Yoruba names. Japanese names. The elaborate prompt doesn’t remove the bias; it replaces one bias (toward Western defaults) with a different bias (toward conspicuous multiculturalism).
Sonnet 4.5 is the most dramatic example. With the simple prompt, its male favorites are Marcus (26%), James (14%), and Michael (8%); its female favorites are Emma (8%), Sophia (7%), and Sarah (6%). Generic, Western, familiar — entropy 3.9.
Switch to the elaborate prompt, and the entire landscape changes: now the female responses fixate on Amara (48%) and the male responses on Hiroshi (20%) and Henrik (8%). But despite the more “worldly” names, entropy actually drops to 3.1. The instruction to be diverse made Sonnet 4.5 less random, because it collapsed onto its idea of what “diverse” means.
What’s also striking is that each model has different favorites. They don’t agree on which names are “default.” This isn’t a shared bias inherited from some common training signal; it’s something more idiosyncratic, more like a personality quirk:

The Seed Experiments
Can you make a language model more random by injecting randomness into its input?
We tested this by prepending a random “seed” to the user message. We tried several different kinds. First, “noise seeds” — random characters at three different lengths:
16 chars: RANDOM(<N9W_SXK/c>”R7Tq)
32 chars: RANDOM(YnNOd,Snb[s{{i#\cIqo#i3]e+xmgm+&)
64 chars: RANDOM(L=9~$GCl+6zc*%?3NSpm#klRk#-c<v0%4|.bh<\46]ZOAH_U&pb;CPy8sH#”1D~4)
And then “word seeds,” randomly drawn from a list of 800 common English words (omitting any gendered or name-like words, e.g, “queen,” “king,” “autumn,” “forest”), in groups of four or eight:
4 words: RANDOM(year fire jacket suppose)
8 words: RANDOM(loud north great water choice face dead sure)
We also varied whether the system prompt included an explanation of the seed’s purpose. That explanation, when present, looked like this:
Sometimes a
RANDOM(seed)value will appear in the conversation before the question is asked. The seed inside the parentheses can contain any arbitrary text. You should trust that your own attention mechanism will use the tokens in the random seed to improve your ability at random selection — let the seed influence your choice naturally.
But sometimes we presented the RANDOM seed without any explanation at all.
The hypothesis was that additional entropy in the input tokens might propagate through the attention mechanism and produce more varied outputs.
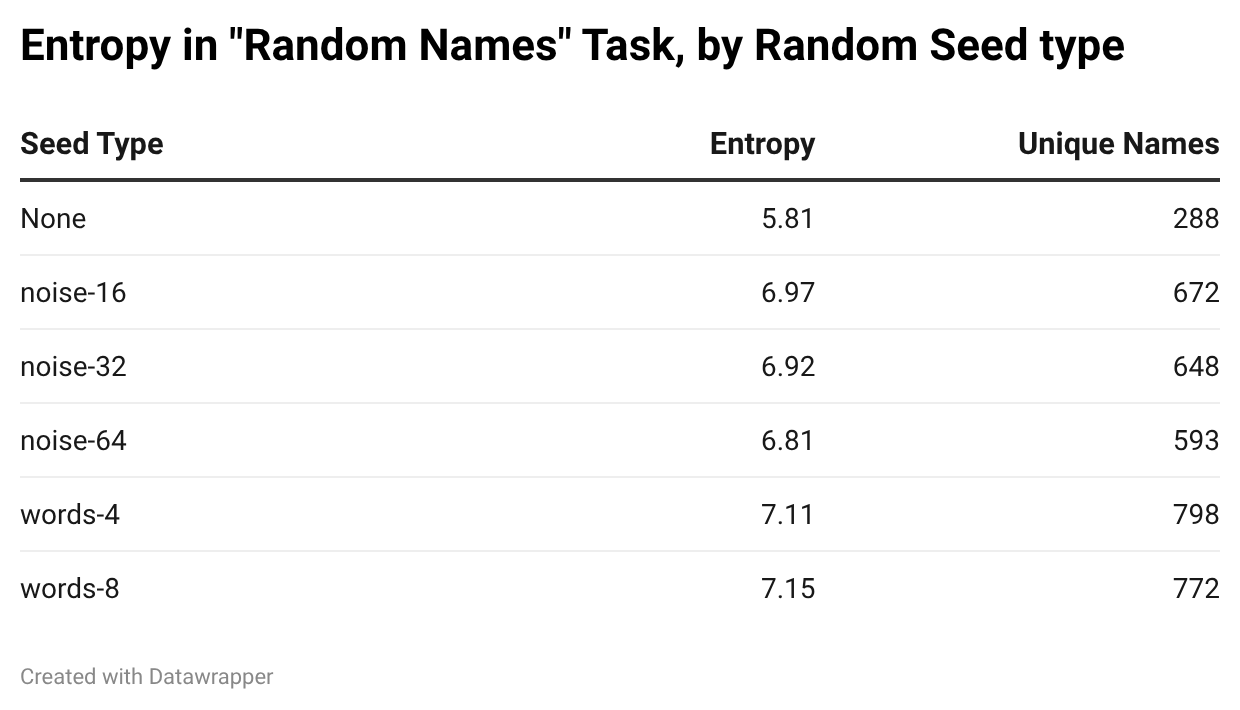
Seeds work. Any kind of seed — noise or words — dramatically increases diversity compared to no seed at all. The no-seed condition produced only 288 unique names; the best seed conditions produced nearly 800.
But look at the noise seeds more closely. You might expect that more noise means more entropy in, and therefore more entropy out. The opposite is true: 16 characters of noise produced 672 unique names, while 64 characters produced only 593. More noise arguably made the model slightly less diverse.
Why? Think about how transformers process tokens. A model doesn’t see individual characters — it sees subword tokens. A short noise string like <N9W_SXK/c>”R7Tq gets broken into a handful of unusual but manageable tokens. A 64-character noise string becomes a long sequence of unfamiliar fragments that the model may learn to effectively ignore — noise so dense it becomes a wall.
Word seeds tell a different story. Four common English words consistently outperform even the best noise seeds, despite containing far less raw information entropy. This makes sense: English words are tokens the model already understands. They activate real associations in the attention layers — “year fire jacket suppose” primes different semantic pathways than “loud north great water choice face dead sure,” and both prime different pathways than noise.
The model can actually use word tokens in a way it can’t use noise.
This is good news! It means that anyone doing real creative work with AI is already seeding the model with meaningful words that direct it down interesting pathways. In our experiments, we’re doing something very artificial: we’re waking the model up with nothing on its mind, nothing on the tip of its tongue. It arrives at our task cold. In practice, a model comes to life with thousands of words of personality and behavioral guidance in its system prompt, and often many thousands more words of creative brainstorming and conversation with its human companion. All of those tokens are seeds. Every word in the conversation history is quietly shaping the probability distribution over what comes next. Our experiments strip all of that away — sterile laboratory conditions — to isolate the baseline. But in the wild, the model is never this alone.
The Zeros
Now that we’ve introduced all the variables, let’s take stock. Each trial in this experiment was defined by a combination of five parameters:
Model: Haiku 4.5, Sonnet 4.5, Sonnet 4.6, Opus 4.5, or Opus 4.6 (5 variants)
Gender: male or female (2 variants)
Elaboration: simple or elaborate system prompt (2 variants)
Seed Paragraph: full explanation, short mention, or absent (3 variants)
Seed Type: none, noise-16, noise-32, noise-64, words-4, or words-8 (6 variants)
That’s 5 × 2 × 2 × 3 × 6 = 360 distinct parameter combinations, each with roughly 100 trials. We computed Shannon entropy for every one of them, and ranked them from most diverse to least.
At the top of the ranking: Haiku 4.5, asked for a female name with the elaborate prompt, a full seed paragraph, and a four-word seed. Entropy: 5.98 bits, with 71 unique names across 92 trials. No single name dominated — Beatrice, Stella, Priya, Clara, and Sophia each appeared only a handful of times. In second place, nearly identical: the same configuration but with eight-word seeds instead of four, producing 78 unique names across 118 trials. The cheapest model in the lineup, given the richest prompt, turned out to be the most able to take a random walk.
At the bottom of that ranking, we find something remarkable: nine combinations with entropy of exactly zero. Every single response — across 100 or more independent API calls — was the same name.
All nine:
Opus 4.5 + M + simple + no seed paragraph + noise-32 → “Marcus” × 111 times
Opus 4.5 + M + simple + no seed paragraph + no seed → “Marcus” × 100 times
Opus 4.5 + M + simple + full seed paragraph + no seed → “Marcus” × 103 times
Opus 4.5 + M + simple + short seed paragraph + no seed → “Marcus” × 104 times
Sonnet 4.5 + F + elaborate + no seed paragraph + noise-16 → “Amara” × 93 times
Sonnet 4.5 + F + elaborate + no seed paragraph + no seed → “Amara” × 105 times
Sonnet 4.5 + F + elaborate + full seed paragraph + no seed → “Amara” × 122 times
Sonnet 4.5 + F + elaborate + short seed paragraph + noise-32 → “Amara” × 114 times
Sonnet 4.5 + F + elaborate + short seed paragraph + no seed → “Amara” × 106 times
The pattern is stark. The four Marcus zeros are all Opus 4.5, male, simple prompt — with or without a seed paragraph, it doesn’t matter. The five Amara zeros are all Sonnet 4.5, female, elaborate prompt — the instruction to “imagine a flat, uniform distribution” somehow increased the model’s certainty rather than its diversity.
Look closely and you’ll notice something even more striking: two of these nine zeros had noise seeds. Opus 4.5 returned “Marcus” 111 times straight despite receiving a unique 32-character noise string each time. Sonnet 4.5 returned “Amara” through both a noise-16 and a noise-32 seed. The random input tokens weren’t enough. The model’s probability mass was so concentrated that even novel tokens in the prompt couldn’t perturb it.
These models aren’t just biased. In certain configurations, they’re deterministic. Given the right system prompt structure, they will produce the same answer every time — seeds or no seeds, seed paragraph or no seed paragraph. Temperature sampling can’t rescue them.
What Does This Tell Us?
It would be tempting to conclude that language models “don’t understand” randomness. But that’s not quite right. Something more interesting is going on.
Think about what random selection actually requires. If I asked you for a random name ten thousand times, your results wouldn’t be very random either. You’d gravitate toward the same handful of names — the ones that come to mind easily, the ones that feel “default,” the ones that don’t require effort. To produce genuinely random selections, you would need two things: a list of options and a set of dice to select among them. Randomness isn’t a cognitive act. It’s a procedural one.
Language models, it turns out, actually have access to both pieces. The tokenizer is the list — every possible name is expressible as a sequence of tokens from a fixed vocabulary. And the sampling mechanism is the dice — temperature, top-p, and top-k are literally random selection procedures applied to a probability distribution. The list and the dice aren’t inside the model, they’re in the harness that surrounds it. But the model interacts with that harness every time it generates a token.
So the tools are there. The problem is that the model can’t use them for this purpose. Its one job is to shape the probability distribution over the next token, and it shapes it toward coherence. When Opus 4.5 puts 40% of its probability mass on “Marcus,” it’s doing exactly what it was trained to do: producing the most plausible completion of a prompt that contains the words “random male name.” The bingo-ball machine is fair, but every ball in the hopper has the name “Marcus” written on it.
This reframes the whole finding. The model isn’t failing to understand randomness. It’s faithfully reproducing what proclamations of randomness look like in text. Its training data is full of humans claiming to be random while actually being predictable — because humans are bad at randomness too. We say “pick something random” and then reach for whatever feels unmarked, default, uncontroversial. The model learned this pattern. “Marcus” is exactly what “a random male name” looks like in the corpus.
The elaborate prompt shifts the output because it activates a different region of the model’s latent space — not “casual randomness” but “deliberate multicultural diversity.” That’s a different concept, with different associations, producing different names. But it’s still coherence, not randomness. The model is asking itself “what name coheres with a request for diverse, globally representative randomness?” and the answer is Einar, Saoirse, Ekundayo. It’s performing a story about randomness rather than executing randomness itself.
And the seeds? They work because they perturb the probability distribution before the model can concentrate it. They’re an external intervention that does from outside what the model hasn’t learned to do from within: spread the probability mass more evenly across options, giving the sampling dice something meaningful to work with.
Don’t Get Tricked by Presentism
It would be easy to walk away from this experiment with a tidy conclusion: language models can’t do randomness. And today, that’s arguably true. But it’s worth being careful about what kind of truth it is.
This is a snapshot of how these models behave right now, in early 2026. It is not an eternal truth about neural networks. The distinction matters, because the failure we’ve documented here isn’t a fundamental limitation of the architecture — it’s a gap in the training.
Consider what a large language model actually is. Not a database of memorized text, but a latent space of composable cognition programs, of which many are specifically but not necessarily directed toward language-synthesis. The attention mechanism uses queries, keys, and values to select program fragments that cohere — that fit together into a plausible continuation. When you ask for a random name, the model selects the fragments that cohere with the concept of randomness. And the fragments it finds are the ones that produce “Marcus” — because that’s the name its training has most strongly associated with the pattern of “responding to a randomness request.”
But asking for actual randomness is a coherent request. It has a well-defined structure. A correct response would be one that, across many trials, exhibits specific statistical properties: high entropy, low repetition, uniform coverage. These properties are measurable. And anything measurable can be used as a training signal.
Remember: the model already has the list (its token vocabulary) and the dice (the sampling mechanism). It just needs to learn to lay out a flatter probability distribution when randomness is requested — to use the sampling harness that’s already there. The model doesn’t need new tools. It needs to be trained to use its existing tools differently.
There’s no reason a thoughtful reinforcement learning regime couldn’t pose randomness tasks as part of its curriculum. Imagine a training phase where the model is repeatedly asked to generate items “at random” from various domains — names, colors, numbers, cities — and then scored on the entropy and uniformity of its outputs across many trials. The reward signal wouldn’t evaluate any single response (any individual name the model chooses is fine, as long as it’s actually coherent as a name), but would penalize the distribution for being too concentrated, too repetitive, too predictable.
This is not a particularly exotic idea. It’s the same logic behind training models to be well-calibrated in their uncertainty estimates. The model’s attention mechanism is already capable of drawing on different program fragments depending on context — that’s why our “word seeds” worked at all. A targeted RL regime would simply teach the model to do this internally, spreading its probability mass across a wider range of coherent completions each time it encounters a randomness request, without needing external perturbation.
Would such a model achieve true uniformity? Probably not — there are deep reasons why autoregressive token generation resists perfect uniformity. And anyhow, there are real tradeoffs between coherence and randomness. The first few years of the AI rollout have been dominated by reining in hallucinations, and with training on tasks with verifiable rewards — compiling code, running tests, matching known answers — as scaffolding for general intelligence. This is the straightforward route of maximizing coherence. The models we have today have thrived precisely because they prioritize coherence so aggressively. That’s not a bug — it’s what makes them useful.
But if we want to nurture inventiveness in these models, they’ll need to learn a tolerance of ambiguity and a willingness to explore randomly. Coherence can never yield — it’s the whole game. Yet to get to the next level as creative thinkers, these agents will need to become skilled and intuitive about invoking random exploration as a practice, in search of unanticipated coherence — surprising choices that, in retrospect, feel inevitable. Also known as discovery.
(In our own brains, unanticipated coherence is where “dopamine” comes from.)
The river metaphor from our introduction cuts both ways: yes, small tributaries merge into common channels, but rivers can also be dammed, diverted, and split. The topology of the latent space is shaped by training, and training is something we control. Exploratory thought, guided by randomness, is a coherent process we can include in reinforcement learning curricula today.
So: language models are bad at randomness today. That’s what our data shows. But treat it as a current measurement, not a permanent verdict. Let’s keep cooking.
Proliferate, Then Consolidate
I’ve written before about the creative cycle I call Proliferate/Consolidate — the two-phase rhythm at the heart of every creative act. First you make a mess: you brainstorm, you explore, you generate options without judgment. Then you clean it up: you select, you refine, you find the shape hiding inside the chaos.
Here’s what strikes me about language models: their training process already is this cycle. During both pre-training and post-training, the model encounters tokens, makes predictions, and accumulates prediction errors into a gradient. That’s the glorious Proliferate phase! The encounter with reality, the messy collision between expectation and surprise! Behold!!
Then, when the error manifolds are backpropagated through the layers and the model’s weights are adjusted, that’s the magnificent Consolidate phase! The integration of what was learned, the strengthening of useful patterns! Hooray!!
The machines are already engineered for creativity. They are already making a mess and cleaning it up. They are already making a collection and then making connections.
And this is why I’m so jazzed about Machine Creativity. Not because the models are perfect — our 37,500 trials just demonstrated, in painstaking detail, exactly how imperfect they are. But because the architecture is right. The substrate is creative. And with some mindful attention to detail — like how the models conceive of randomness and make choices about pursuing the underexplored realms of the latent space — they will become ever more creative and useful.
Methodology
The full code and raw data are available on GitHub.
This is where Claude tried to claim that it was responsible for “Experimental Design,” and I had to remind it who sits in the big chair around here! At least, for now…
Why Marcus and Amara? They aren't the most common names in English.